Kubernetes nodes for cloud engineers

Here, you will find out best practices when related to kubernetes nodes for you as a cloud engineer, plus the relevant components involved. For an engineer is essential to be familiar with the terms and mechanisms here, especially when troubleshooting a workload together with the infrastructure team.
Main and worker nodes
As depicted in the following image, there are two types of nodes. A cluster has a main node (in the past known as master) and multiple worker nodes.
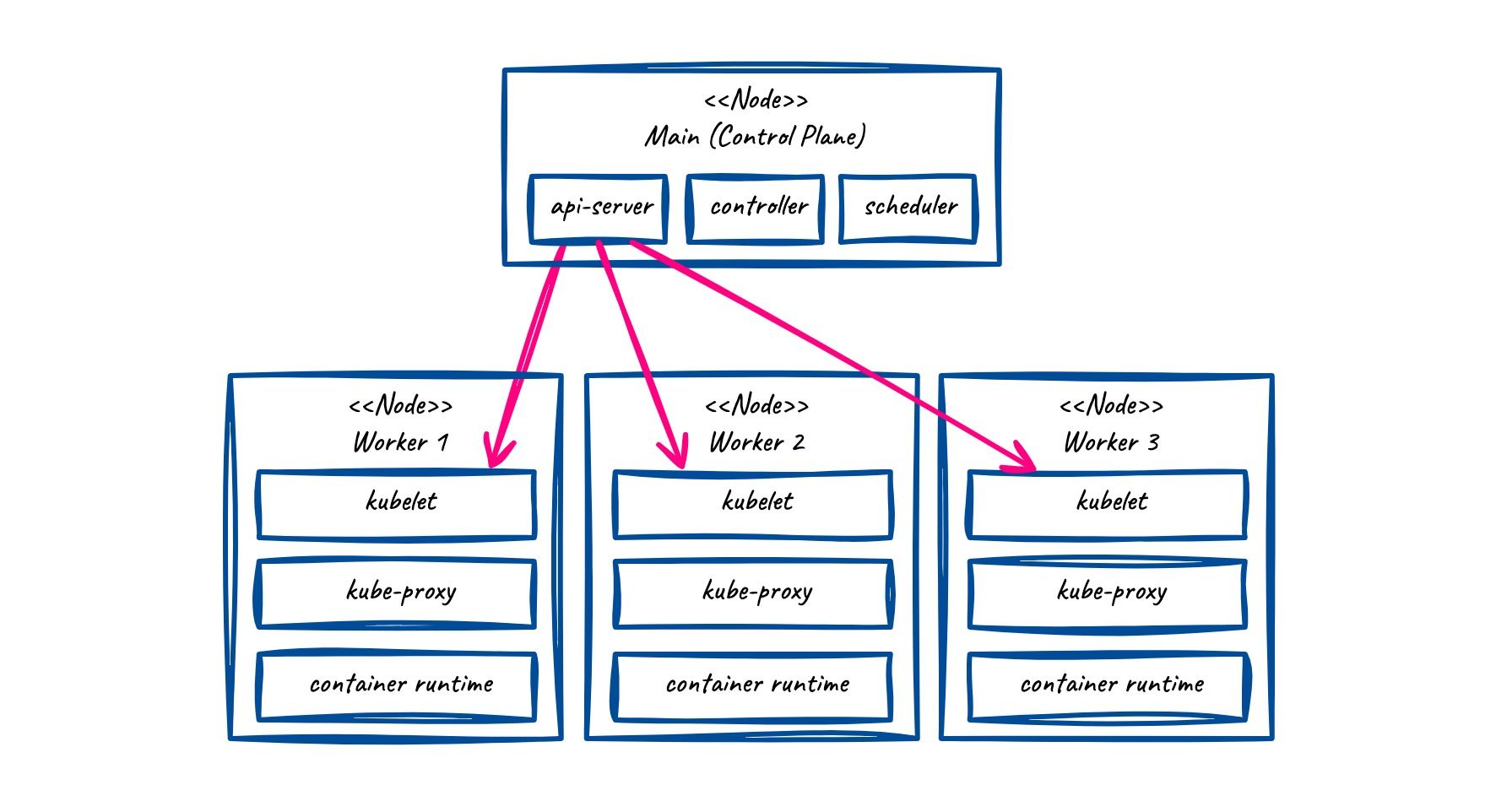
Node components: main node
The main node, also referred to as the control plane, contains three components: The API server, Controller Manager, and Scheduler. The API server is the component that allows to programatically manage the cluster. You actually use it when typing kubectl commands. The Controller Manager is the governance of the cluster and ensures the desired state. Imagine an endlessly running loop that checks the system. Finally, the Scheduler will allocate resources to the node. It decides, for example, which node hosts a newly spun up pod.
Node components: worker node
The worker node runs: kubelet, kube-proxy and container runtime. Kubelet ensures that the containers are running in the pods. It communicates with the control plane (main node) and ensures the desired state on the respective node. Kube-proxy allows incoming traffic and routes it to the pods. The container runtime – this is usually Docker that is running on the node. Others are CRI-O or containerd.
Best practices for developers
Since Kubernetes nodes are running on a hardware machine, they come with limitations. Below, you see how pods on a node are using up the memory available to a worker node.
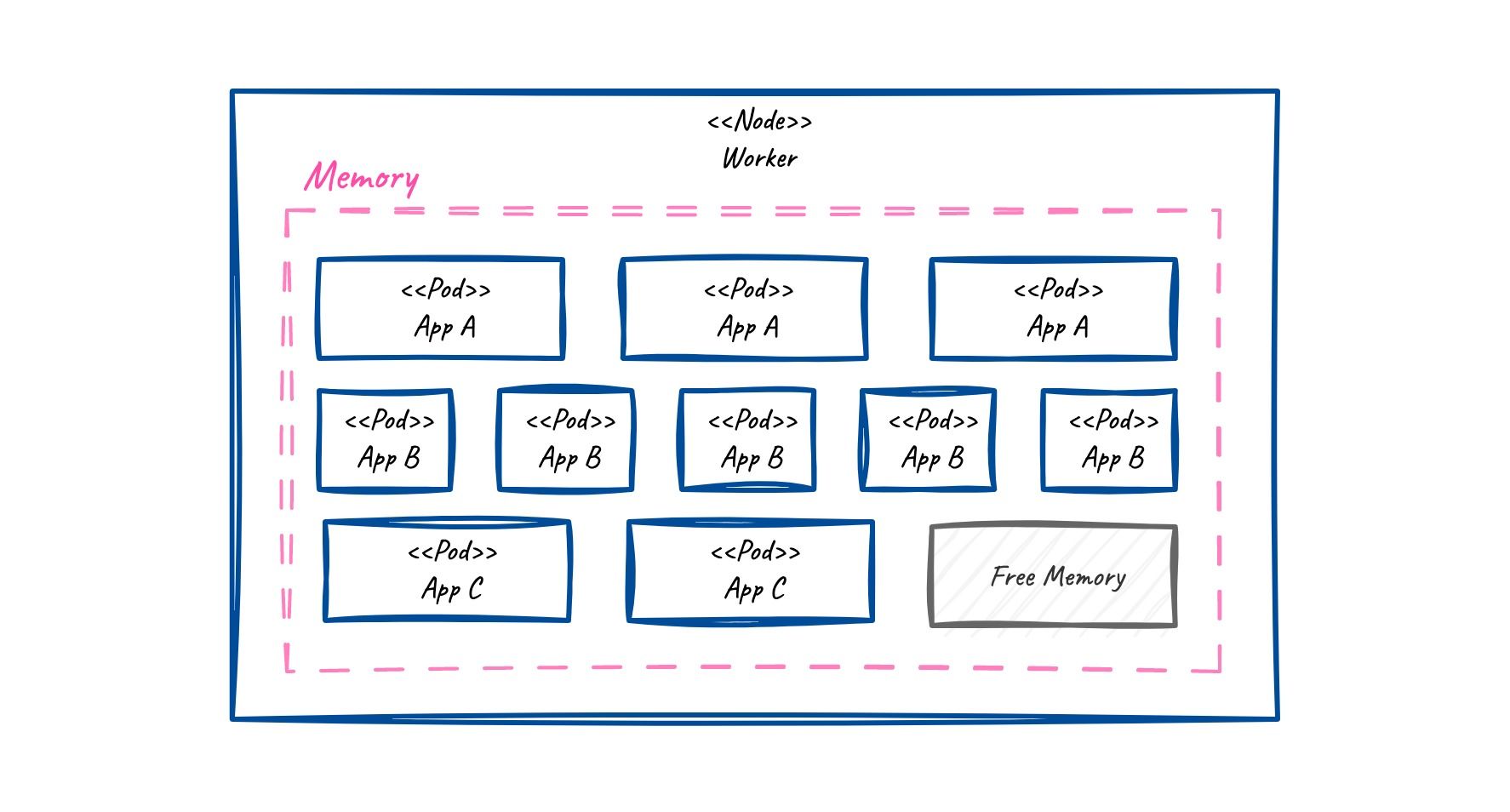
Resources like CPU, memory and storage are finite. A best practice is to configure resource limits on your containers. This allows k8s to do efficient resource allocation, but also enables the development team to be more aware and detect if there is something off (like a memory leak). Moreover, set up horizontal-pod-autoscaling (HPA) to ensure that your application only used the resources that it needs and does not have a high baseline.
Regarding critical storage mechanisms, it is recommended to use a scalable storage solution like AWS S3 or Azure Blob Storage. These solutions are more reliable than the statically sized disk on a machine.
Network traffic limitations. Communication of pods within a node is okay. If pods communicate across nodes, this can congest the network traffic and cause latency. Generally, it is advised to not rely on pod-to-pod communication but use asynchronous communication and patterns like queueing.
In doubt: Talk to your infrastructure team. They will be able to give you guidance. Every context and workload is different and requires weighing the pros and cons. Especially when you set up a new service that is doing more than routing request to upstream services and mapping the response data.
Node monitoring
There should be monitoring provided and used by your operations team. Another suitable option is the Kubernetes Dashboard – especially if working on a local machine.